Specbee: How To Use The Power of Cron Jobs for Task Automation in Drupal
PreviousNext: Introducing Symfony Messenger integrations with Drupal
Part one in a series of posts introducing Symfony Messenger, its ecosystem, and unique Drupal integrations to Drupal developers.
by daniel.phin / 9 January 2024The SM project brings Symfony Messenger and its ecosystem together with Drupal.
Symfony Messenger is a powerful alternative to Drupal’s @QueueWorker, enabling real-time or precise execution of scheduled tasks. It’s also a viable replacement for hook_cron enabling you to schedule dispatch and processing of messages according to crontab rules, again in real-time, rather than waiting for server-invoked or request-termination cron.
Messenger can be used as a user-friendly alternative to Batch API, as the user's browser is not blocked, while integrations such as Toasty can be programmed to notify when the last of a “batch” of messages completes, communicating to the user via user-interface toasts.
The Drupal integration includes additional niceties, such as intercepting legacy QueueWorkers for processing data through the Symfony Messenger bus, and end-user UI notifying a user when tasks relevant to them have been processed.
During this and the following series of posts, we’ll be exploring the benefits of real-time processing and user-friendly features that improve the overall experience and outputs.
The workerToasty displaying notifications.MessengerFirst up, we’ll cover the main features of Symfony Messenger and how it works.
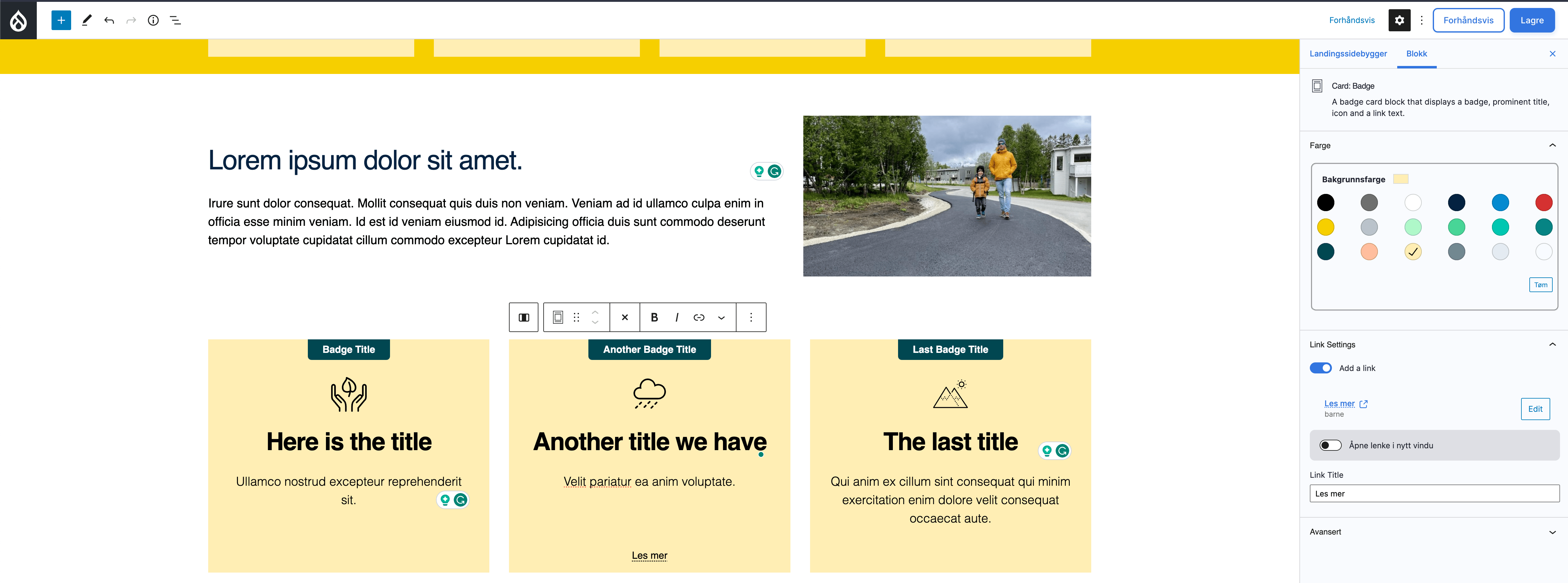
As a developer working with Messenger, the most frequent task is to construct message and associated message handlers. A message holds data, while a message handler processes the associated data.
A message is inserted into the bus. The bus executes a series of middleware in order, each of which can view and modify the message.
If a transport is configured, the message may be captured and stored for processing later.
Typically the bus, middleware, and transports are configured in advance and rarely changed. Message and message handlers are introduced often without needing other configuration.
- Message — an arbitary PHP object, it must be serialisable.
- Message handler — a class that takes action based on the message it is given. Typically a message handler is designed to consume one type of message.
- Middleware — code that takes action on all message types, and has access to the containing envelope and stamps.
- Bus — a series of middleware in a particular order. There is a default bus, and a default set of middleware.
- Envelope — an envelope contains a single message, and it may have many stamps. A message always has an envelope.
- Stamp — a piece of metadata associated with an envelope. The most common use case is to track whether a middleware has already operated on the envelope. Useful when a transport re-runs a message through the bus after unserialisation. Another useful stamp is one to set the date and time for when a message should be processed.
- Transport — a transport comprises a receiver and sender. In the case of the doctrine database transport, its sender will serialise the message and store it in the database. The receiver will listen for messages ready to be sent, and then unserialise them.
- Worker — a command line application responsible for unserialising messages immediately, or at a scheduled time in the future. Messages are inserted into the bus for processing.
The stars of the show are buses. One bus is ready out of the box, which comprises a series of ordered middleware. A message is dispatched into a bus, where each middleware has the opportunity to view and modify the message (and its envelope). It's unlikely you’ll need to think about middleware, as the default set may already be the perfect combination.
When a message is dispatched to a bus, you can choose to wrap it in an envelope and apply stamps like the DelayStamp . A message will always be wrapped in an envelope if you don’t do it explicitly.
Buses have a series of default middleware. The main middleware to note are the transport and message handler middlewares. When a transport is configured for messenger, the transport middleware will capture the message, serialise it, and store it somewhere. For example, a database in the case of the doctrine transport. Any middleware after the transport middleware are not executed, for now.
When running the worker, you are opting to choose which bus and transport to run. The command will listen for messages as they are stored, and if the time is right, messages will be unserialised and inserted into the bus. The message will begin its journey yet again, iterating through all the middlewares from the beginning. When the transport middleware is hit, it will detect the message has already been in the transport to prevent recursion. This is done by checking the ReceivedStamp stamp added to the message envelope.
Transports: synchronous, asynchronousOut of the box, when a message is dispatched into the bus in a CLI or web request, it will be processed synchronously. All middleware will operate on the message in a set order, including the message handler middleware.
The greatest advantage of using Messenger is the ability to asynchronously handle messages outside of the thread they were originally dispatched. That is: asynchronously. This can be useful for improving the web request response times and reducing the memory usage and limit of web requests (allowing for more FPM threads on a machine). Bulky business operations that would typically, or should be, constrained by the limits of the web thread have more breathing room. A CLI runner/container may be set up with a little more memory and processing capability with the explicit direction to listen for messages and handle them in real-time, either as soon as possible or as scheduled.
Upcoming posts in this series will dive into aspects of Symfony Messenger and SM:
- Symfony Messenger’ message and message handlers, and comparison with @QueueWorker
- Real-time: Symfony Messenger’ Consume command and prioritised messages
- Automatic message scheduling and replacing hook_cron
- Adding real-time processing to QueueWorker plugins
- Making Symfony Mailer asynchronous: integration with Symfony Messenger
- Displaying notifications when Symfony Messenger messages are processed
- Future of Symfony Messenger in Drupal
The next post covers the implementation of a message and message handler, and a comparison with Drupal core’s @QueueWorker plugins.
Tagged Symfony, Symfony MessengerTalking Drupal: Talking Drupal #432 - Portals & Community Websites
Today we are talking about Portals, Community Websites, and Drupal with guest Ron Northcutt. We’ll also cover Private Message as our module of the week.
For show notes visit: www.talkingDrupal.com/432
Topics- Why are you passionate about community sites
- Different types of portals you’ve worked on
- Common features
- Why is Drupal a great fit
- Why would you choose Drupal over a Saas or PaaS
- What is unique about each community
- How important is UX
- What common content models do you see
- Most important tip
- Lego sorting
- PHPBB
- discourse
- Open Social
- Monday
Ron Northcutt - community.appsmith.com rlnorthcutt
HostsNic Laflin - nLighteneddevelopment.com nicxvan John Picozzi - epam.com johnpicozzi Martin Anderson-Clutz - mandclu
MOTW CorrespondentMartin Anderson-Clutz - mandclu
- Module name/project name:
- Brief description:
- Have you ever wanted to include a full-fledged, ajaxified system for private messages between users on your Drupal site? There’s a module for that
- Brief history
- How old: created in Apr 2017 by Jaypan, a fellow Canadian, but the most recent release is by Lucas Hedding, who hails from Nicaragua, and is a prolific contrib maintainer in his own right
- Versions available: 8.x-2.0-beta18 and 3.0.0 versions available, the latter of which works with D9 and 10
- Maintainership
- Actively maintained, latest release in Oct 2023
- Number of open issues: 130, 4 of which are bugs on the 3.0.x branch
- Test coverage
- Documentation: does have a handbook, though the pages seem to date back to 2017, so hopefully the installation and setup hasn’t changed too much since then
- Usage stats:
- Almost 2,000 sites
- Maintainer(s):
- Module features and usage
- With the Private Message module installed, users on your site can have permissions-based access to send private messages to each other
- Messages and threads are fieldable entities, and in general the module is made to be highly configurable, so you can tailor it to meet your site’s specific needs
- That includes the frequency for asynchronous operations like loading new messages, which can be done without a full page refresh. There’s also a companion module to use Node.js for the asynchronous operations, to reduce load on both the browser and the server
- That also allows for browser push notifications, or you can use the integration with the Message module to send notifications via email, SMS, and more, including aggregating the notifications into digests
- Companies often have a dedicated messaging solution like Slack or Teams that they use internally, but this can be a good solution for an extranet or vendor portal, where the users may represent a variety of organizations
- It’s also worth mentioning that both Private Message and Message are included in the Open Social distribution, so that could be a way to try out a preconfigured setup
Ramsalt Lab: Drupal 7 security support will end - now is the time to plan a migration to Drupal 10!
Drupal has been a robust choice for building and maintaining websites for decades. Like all other CMS systems, technological advancements and security requirements continually evolve at rapid speed and older software versions will be taken off the market.
In January 2025 Drupal 7 will finally reach its End of Life after 14 successful years and the necessity to transition to Drupal 10 has never been more critical.
Source: Drupal 7 End of Life | Drupal.org
This means the Drupal community and the official development team will stop providing support, including crucial security patches and updates. Without these updates, weaknesses in the system remain unaddressed, leaving websites vulnerable to dangerous cyber threats and data exploitation.
46,5% of all Drupal sites are still running on version 7
Source: Usage Statistics and Market Share of Drupal, January 2024 (w3techs.com)Your company isn't just facing a hard deadline to relaunch your new site as January 2025 grows closer. You’re also competing with a vast number of organizations just like yours that need to coordinate the same migration process.
It is important to understand that depending on the complexity of the website the migration from Drupal 7 to Drupal 10 is not just a simple update. The data structure and design need to be rebuilt and major technical updates executed. Ramsalt has migrated numerous of clients from Drupal 7 to Drupal 10 and have built a team of migration experts for a successful migration process.
Get an offer for the migration and make sure that your company stays agile and competitive:
Yngve Bergheim, yngve@ramsalt.com
Why should you migrate from Drupal 7 to Drupal 10?
The foremost reason to migrate from Drupal 7 to Drupal 10 lies in security. Yet, Drupal 10 brings automated updates, improved user experience, along with several other feature improvements. See our blog article: A new year, A new shiny Drupal 10 | Drupal | Ledende leverandør | Ramsalt.
Below we want to list some of the Drupal 10 highlights:
CKEditor 5 update from CKEditor 4 - With a thorough rebuild and an exciting new feature set, CKEditor 5 gives Drupal 10 a modern, collaborative editor experience. Users of programs like Microsoft Word or Google Docs will be used to the new CKEditor's interface. It also offers common tools for collaboration like comments, change suggestions, version histories, and other accepted editing practices.
CKEditor 5 in Drupal
Try it our yourself here: Feature-rich editor - CKEditor 5 demo
Gutenberg Editor - With the latest Drupal 10 update, we are capable of using the most loved content editor. Here are some key points about the Gutenberg editor in the context of Drupal:
User-Friendly Interface: Gutenberg provides a more intuitive and visual editing experience. It uses blocks to represent various content elements like text, images, and videos, making it easy for users to build and design their content layout.
Enhanced Content Creation: With Gutenberg, content creators can design more complex layouts without needing any extensive technical knowledge. It offers a wide range of customization options within each block, making it easier to design diverse and dynamic web pages, we even have our own Gutenberg landing page builder in-house. the limits are your imagination.
Responsive Design: Blocks in the Gutenberg editor are inherently responsive, ensuring that content created in Drupal looks good on all devices.
Extensibility: Just like Drupal, Gutenberg is highly extensible. Developers can create custom blocks to add new functionalities, tailored to specific needs.
Gutenberg in Drupal{kind=link}
{kind=link}
Try it out for yourself: Drupal Gutenberg demo
Improved Admin and Design ThemesDrupal 10 introduces a significantly enhanced theming system, characterized by its streamlined single-directory component structure. This advancement not only boosts overall performance but also accelerates the rollout of new features. Furthermore, it offers comprehensive editing capabilities, enabling a seamless top-to-bottom customization experience. This modernized approach in Drupal 10 ensures a more efficient, user-friendly, and agile development process, catering to the evolving needs of end-users and editorial teams alike.
Improved Website Performance & SecurityDrupal 10 improves your site security by including up-to-date protocols and technical dependencies such as PHP 8.2, Symfony 6.2. This means a faster and more modern website out of the box.
With enhanced dynamic caching (BigPipe) reduces page load times by invalidating only the content that has changed and therefore provides a faster and better user experience.
Drupal 10 also marks the end of Drupal 7’s jQuery. A large JavaScript library, jQuery was a powerful tool, but modern browsers perform many of the same functions. The up-to-date JavaScript used by Drupal 10 also decreases page load times and snappier behavior for the end users.
Source: Drupal 10 | Drupal.org & Drupal 10.2 is now available | Drupal.org
Lisa Streeter: Setting Order Number before Payment Transaction
In Drupal Commerce, carts do not have order numbers. Order numbers are not set until checkout completion, when the order is placed. If the order type has been configured with a number pattern, that pattern is used to generate the order number; otherwise the order entity ID is used. As a result, when a credit card payment is added during checkout, the cart/order may not have its final Order Number yet. For some payment gateways, this is fine--only the order entity ID is needed.
Lisa Streeter: Payment by Purchase Order
A Drupal Commerce website may want to offer the same payment terms provided to customers purchasing products offline. If up-front payment is not required, then we need to create an option for customers to complete checkout without providing payment. Additional information may need to be collected during checkout for the "payment on account" option in lieu of a traditional payment method. For our business needs, this additional information takes the form of a Purchase Order number entered by the customer.
Lisa Streeter: Editing "Placed" Orders
When a customer completes checkout on a Drupal Commerce website, the cart order is "placed." No additional changes can be made to the order by the customer. Administrative users, with access permissions, can typically edit these "placed" orders. However, significant changes like the addition/removal or an order item or an order item quantity/pricing change can be problematic. The changes can be made, but... afterwards, things like taxes, discounts, shipping charges, etc. may not be correct.
Lisa Streeter: B2B Address
When a store has customers that are businesses or institutional, the standard Address field properties and formatting may not align well with actual billing and shipping addresses. For example, a business address may not include the customer's first and last name as the first line; instead, an organizational name may be used. If a contact name is included, it may be an "Attention" line. Additionally, businesses may require a line with reference or purchase order number.
Lisa Streeter: Order Receipt Resend Copy
Drupal Commerce order types can be configured to email the customer a receipt when an order is placed, with or without a BCC copy sent to a specified email address. Additionally, administrative users can use a "Resend receipt" button to send a receipt to the contact email address set for the order; no copy is sent to an additional email address.
When re-sending an order receipt, administrative users may want to:
Lisa Streeter: Order Receipt Preview
Administrative users creating and updating orders in the backend may want to:
- Preview the order receipt before emailing customers.
- Send a copy of the order receipt to an email address other than the contact email address for the order.
Developers may want to:
- Preview the order receipt for testing purposes when working on environments with outgoing emails disabled
We can add a button to the right of the existing, "Resend receipt" button that appears on Order View pages, like this:
Lisa Streeter: Conditional Order Receipts
Core Drupal Commerce provides Order Receipt functionality. An Order Receipt is an email notification sent to a customer when an order is placed. It lets the customer know that the order has been received and includes a summary of the order. For each Order Type, you can turn order receipts on/off and, if enabled, specify that a copy be sent to a specific recipient.
The Drop Times: TDT is a Media Partner for Drupal Mountain Camp 2024
DrupalEasy: Test-driving the Rancher Desktop Docker provider with DDEV on MacOS
Recently, Randy Fay of the DDEV project blogged about two new Docker providers available (and supported by DDEV) for MacOS: Rancher Desktop and OrbStack. Both of these join Colima and Docker Desktop as supported Docker providers for DDEV on MacOS.
What is a Docker provider?I know that I certainly have asked this question - more times than I care to admit. As Randy explains in the blog post:
All of the Docker Providers on every platform (except Linux) are actually wrappers on the open-source Docker/Moby project, which is supported by Docker, Inc.
In other words, in order for DDEV to talk to Docker, it needs a provider. But, not all Docker providers are created equal. Neither Docker Desktop nor OrbStack are open-source - both have free versions (with restrictions); for most commercial use cases, there is a cost involved. Colima and Rancher Desktop are both open-source.
Features vary between Docker providers as well, so it only makes sense that performance differences also exist. Fortunately, Randy has written another blog post summarizing the performance differences between the various Docker providers on MacOS.
tl;dr if you have Mutagen enabled with DDEV, then they're all pretty fast, with OrbStack having the edge.
Why switch Docker providers?While Colima is (IMHO) heads-and-tails better than Docker Desktop for Mac, upgrading Colima itself has been a bit of a rocky road. I have learned to never assume that my databases will remain intact during a Colima upgrade. This usually isn't a deal-breaker, but for me, it is squarely in the inconvenience category.
I'm hoping that the situation is smoother with Rancher Desktop.
Getting started with Rancher DesktopAs I (currently) use DDEV on MacOS with Colima (and Mutagen enabled,) I decided to give Rancher Desktop a try, as it is an open-source option.
Using the instructions provided by the DDEV project, I downloaded Rancher Desktop from the official site. A bit surprisingly, the recommended installation method was not Homebrew, but rather a bit of an old-school MacOS .dmg file.
After downloading Rancher Desktop (but before installing it,) the steps I took to install and change over from Colima began with:
$ ddev poweroff $ colima stopNext, I double-clicked to install Rancher Desktop - making sure to uncheck the "Kubernetes" checkbox as the DDEV instructions suggested. I didn't touch any other settings during the Rancher Desktop install.
Once that was installed, I restarted my Terminal app, then navigated to one of my DDEV projects.
$ cd ~/sites/d10 $ docker context use rancher-desktop $ ddev startIf you haven't used it before, the docker context use rancher-desktop bit basically tells Docker which provider to use. In other words, you can have multiple providers installed (like I do with Colima and Rancher Desktop) and switch between them using the docker context use command.
With that, installation was complete.
My experience with Rancher DesktopIn short: uneventful (in a good way)
I didn't have any issues at all - it all went very smoothly. From a performance standpoint, Drupal 10 sites feel a little bit snappier than with Colima, but this is purely qualitative, not quantitative.
The (minor) downsideWhen switching Docker providers, while project code isn't touched, unfortunately, project databases don't automatically come along. In his blog post, Randy suggests using ddev snapshot --all as an initial step in the process to back up all databases. I tend to take a more piecemeal approach - individually exporting databases while using Colima, then importing them while using Rancher Desktop. For example, here's my process for moving a database from Colima to Rancher Desktop (assuming my system is currently using Rancher Desktop):
$ cd ~/sites/d10 $ ddev poweroff $ colima start $ docker context use colima $ ddev start $ ddev export-db > db-backup.sql.gz $ ddev poweroff $ docker context use rancher-desktop $ ddev start $ ddev import-db –file=db-backup.sql.gz $ ddev drush crGranted, it's a bit wordy, but it works for me.
So, Orbstack?At the present time, I have no plans to test-drive Orbstack. While Randy's blog post does indicate I would experience a minor performance boost, at this time, I'd rather just stick with an open-source solution.
One of our Professional Module Development course graduates, Jay Volk, recounted his recent experience with Orbstack:
My experience is that OrbStack is really fast and while not open source (it's $8/mo.) it seems well worth the cost and I'm happy to support this project. Orbstack will take your existing Docker settings and move them to Orbstack when starting up (it asks your permission.) This proved to be no problem for DDEV but occasionally causes problems with the other solution I sometimes need, Lando. Easy enough, Docker can reclaim settings back from OrbStack and with a Docker restart you're good to go again with that (albeit slower) solution.
ConclusionI wrote the first draft of this blog post about 2 weeks ago - since then I've stuck with Rancher Desktop and have no plans to go back to Colima. I'm pretty sure the performance is a bit better than Colima and I've had absolutely zero issues. The real test (for me at least) will be when it comes time to update Rancher Desktop - assuming it is a smooth experience, I doubt I'll be returning to Colima.
Header image generated by ChatGPT-4 using the prompt: "Create a cartoon image of a cowboy lassoing a giant laptop computer using 2:1 aspect ratio". If someone could identify the two flying objects to the right of the laptop, I'd be most appreciative.
- « erste Seite
- ‹ vorherige Seite
- …
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46